Wie ich einmal auszog, einen Twitterbot zu bauen
Ich bin mittlerweile schon recht lange auf Twitter. So lange, dass, als ich mit dem Twittern begann, der legendäre Account @horse_ebooks noch aktiv und es unklar war, ob es sich bei diesem um einen Bot oder eine reale Person handelte – am Ende stellt es sich als - lange vorbereitetes - “viral marketing” heraus.1
Anfang der 2010er waren Bots auf Twitter nicht so allgegenwärtig wie heute, zugleich waren sie nicht so negativ konnotiert. Gerade im Kontext der Phrase “Russian Bot” ist der Twitterbot zum Insignium automatisierter Manipulation und Falschinformation geworden. Twitter selbst versucht strikt dagegen vorzugehen: Immer wieder werden massenweise “fake accounts” gelöscht, allein im Mai und Juni 2018 waren es 70 Millionen.2
Im Jahr 2017 machten Twitterbots nach konservativen Schätzungen etwa 15-16% der Nutzerbasis aus,3 gleichzeitig sind Bots für etwa 2/3 der geteilten Links verantwortlich.4 Unter dieser immensen Masse an Twitterbots finden sich allerdings auch faszinierende Experimente und Services, die zeigen, wie nützlich oder lustig Twitterbots sein können.
Neben unzählingen ebooks-Accounts, die per Markow-Ketten aus verschiedensten Kopora Tweets generieren, gibt es Projekte wie NYT Diff, ein Twitteraccount, der Überschriften und Anreißer der New York Times auf Veränderungen überprüft und die Differenzen zwischen den Fassungen postet, MobyDickatSea, ein Twitterbot, der Sätze aus Moby Dick twittert, oder den G̸l̵i̶t̷c̷h̸ ̵T̵V̶ ̸B̴o̷t̵, der aus Fernsehmaterial verpixelte Kunstwerke kreiert. Eine ganze Reihe künstlerischer Twitterbots hat auch Gregor Weichbrodt erstellt, eine Übersicht lässt sich hier finden.
Von der Idee zum Korpus
Ich war und bin also bereits lange fasziniert vom automatisierten Twittern, hatte aber bis vor recht kurzer Zeit kein ausreichendes Verständnis von Programmierung, um ein Twitterbot-Projekt umzusetzen. Jetzt, mit einem Grundwissen der Programmierung in Python, war endlich die Grundlage für ein einfaches Botprojekt gegeben. Doch dies ist nur ein Teil eines längeren Prozesses: Wenn man einen Bot bauen will, sollte man auch wissen, was genau dieser denn twittern soll – nicht nur, aber auch, weil Twitter genau das wissen will, wenn man einen Developer Key beantragt.
Die Idee für @BT_Zwischenrufe entstand während eines Frühstücks, bei dem ich, aus einem mir im Nachhinein unerfindlichen Grund, eine Bundestagsdebatte auf Phoenix mitverfolgte. Während meines Bachelorstudiums hatte ich mich eine Zeit lang für den recht neuen Bereich der Politolinguistik interessiert und Überlegungen zu Möglichkeiten quantitativer politolinguistischer Forschung anhand der Bundestagsprotokolle angestellt. Denn gerade in diesen wird doch die Sprache des Parlaments offenkundig.
Daraus wurde erstmal nichts, aber ich erinnerte mich daran, als ich an diesem Morgen eine Rede mit besonders vielen Zwischenrufe mitverfolgte. Der Plan kam auf, diese Zwischenrufe in die Timeline zu rufen. Bei etwa 250 Sitzungen pro Bundestagsperiode gibt es mehr als genug Material und die Protokolle folgen einer normierten Struktur, was Auswertungen einfacher macht.

Abb. 1: Beispiel der Formatierung für Zwischenrufe (Sitzung 16/210)
Diese offiziellen Protokolle zu bekommen ist zunächst einmal kein großes Problem, sind doch die PDFs leicht erreichbar auf dem Bundestagsserver und folgen der URL-Struktur https://dip21.bundestag.de/dip21/btp/XX/XXXXX.pdf. Die erste Nummer ist die Zahl der Wahlperiode des Bundestages, beispielsweise 16, und die zweite Nummer die Zahl der Wahlperiode zusammen mit der Sitzungsnummer, beispielsweise 16001. Mit einer einfachen for-Schleife sind alle Protokolle schnell abgerufen und durch das Package textract ist auch die Konvertierung ins weit praktischere Plain-Text-Format unproblematisch.
Knifflig wurde es erst, als ich mit den Textdateien arbeiten wollte: Nicht nur musste ich mir überlegen, wie bestmöglich die Zwischenrufe aus den Textdateien herausgefiltert werden könnten und – eine noch viel mühsamere Angelegenheit – wie mit den hardcoded Zeilen- und Silbenumbrüchen umzugehen sei. Am Ende bestand mein Code aus fünf Schritten, die es ermöglichen, zuverlässig Zwischenrufe zu extrahieren.5
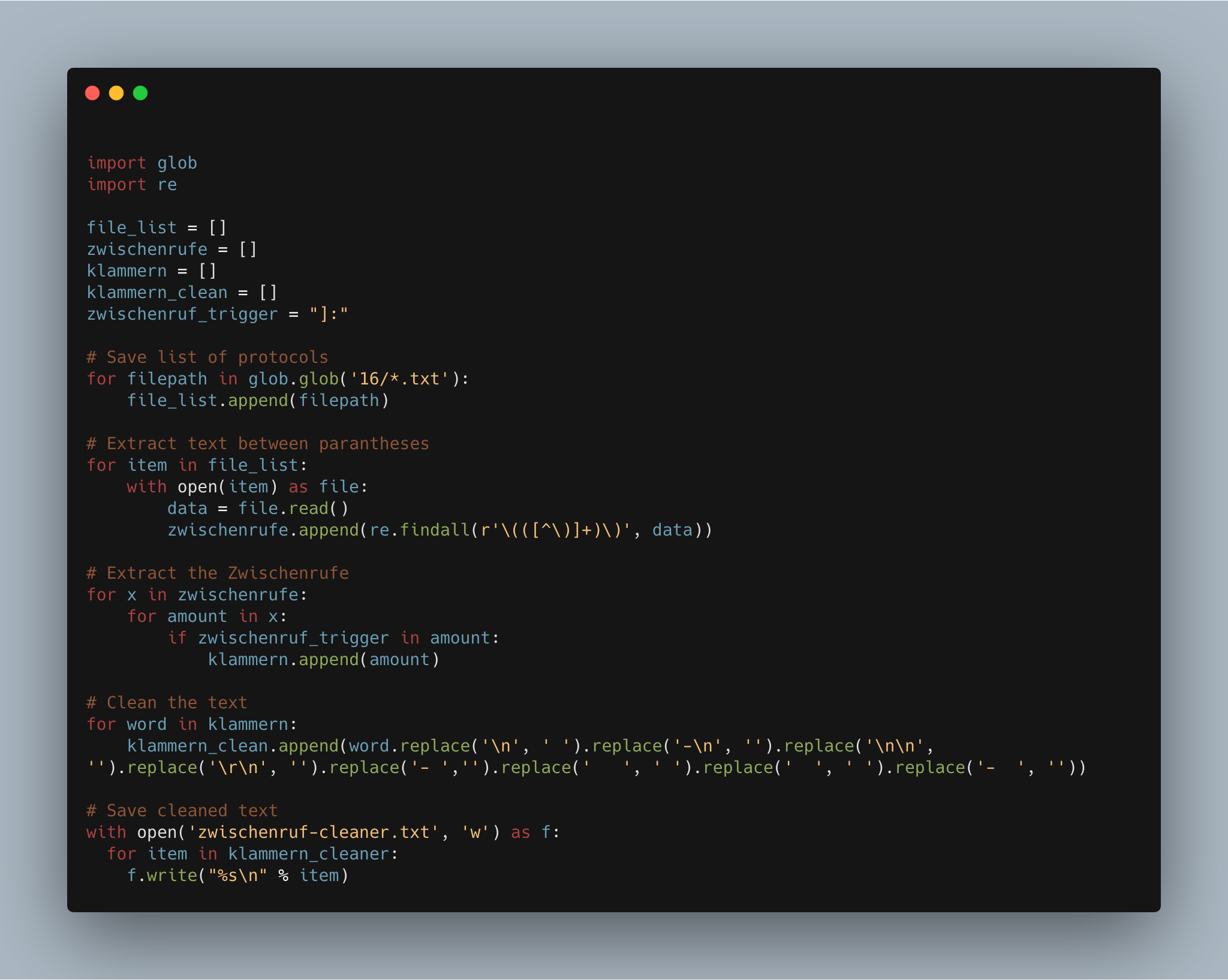 Abb. 2: Code für die Extraktion und Bereinigung des Textkorpus
Abb. 2: Code für die Extraktion und Bereinigung des Textkorpus
Zunächst wird eine Liste mit den filepaths der txt-Protokolle erstellt, durch die im weiteren Verlauf geloopt wird. Jede der Dateien wird geöffnet und jeder String, der in runden Klammern steht, wird einer Liste hinzugefügt. Die erzeugte list of lists beinhaltet neben den Zwischenrufen auch Strings mit Informationen zu Drucksachennummern etc., was natürlich nicht erwünscht ist.
Um die Zwischenrufe zu isolieren, wird die Formalisierung der Protokollstruktur genutzt: Jeder Zwischenruf wird mit dem Namen des unterbrechenden Parlamentariers und dessen Partei gekennzeichnet, wobei die Partei in eckigen Klammern steht. Nur Strings, die diese eckige Klammer, gefolgt von einem Doppelpunkt, enthalten, werden in die Liste “Klammern” aufgenommen. Anschliessend werden mögliche Artefakte der PDF-Konvertierung mit replace() behoben, die Ersetzungsregeln sind Folge eines trial&error-Verfahrens. Zuletzt wird die erzeugte Liste noch in einer Textdatei gespeichert.
Vom Korpus zum Tweet
Bereits eine kurze Recherche zeigte: Es gibt eine Menge Anleitungen für den Bau von Twitterbots im Internet, doch alle beginnen mit der Beantragung eines Developer Keys. Da ich bereits für meine Netzwerkanalyse, eine App anmelden musste, hatte ich daher zunächst ein Problem: Jeder Developer-Account muss mit einer Telefonnummer assoziiert sein, jedoch hatte ich meine einzige Telefonnummer bereits mit eben dem Account verbunden, über den die Netzwerkanalyse durchgeführt wurde.
Um mir keine neue Telefonnummer zulegen zu müssen, habe ich die Vorgehensweise von Molly White übernommen,6 die ich jedoch erst nach einigem Googlen fand:
- Choose an account to use as your developer account and associate your phone number with it.
- Create a new account for your bot.
- Register the Twitter app for the bot on the developer account.
- Head over to Twitter API support and select “I need to transfer an API key to another account”.
- Fill out the form (make sure you’re still signed into the developer account).
- Wait an arbitrary amount of time (it’s usually been about a week for me, but sometimes much longer) for someone at Twitter Support to manually transfer the key.
- Grumble about how there’s got to be a better way to do this.
In meinem Fall hat die Übertragung zwischen den Accounts lediglich drei Tage gedauert, aber angesichts des bereits oben besprochenen PR-Problems der Bots ist die Langsamkeit des Prozesses durchaus angebracht.
Nachdem ich zunächst vor hatte, den Bot über den PaaS-Anbieter Heroku zu betreiben, stellte sich nach einigem Herumsuchen auf Twitter heraus, dass Heroku Mitte 2018 seine Preisstruktur änderte, was den kostenfreien Betrieb eines Twitterbots scheinbar problematisiert.7 Ich bin bisher auf keine optimale Alternative gestossen, auch wenn etwa Glitch sehr vielversprechend aussieht.
Um den Bot zu verwirklichen, auch ohne eine Serverlösung zur Verfügung zu haben, griff ich daher zunächst auf den kompakten randomsentencebot des Github-Users hugovk zurück, der genau das macht, was ich möchte: “Tweet a random line from a text file.” Ein Cronjob sorgt letztlich dafür, dass der Bot regelmäßig - oder sagen wir besser semi-regelmäßig - Zwischenrufe in die Timeline wirft.
Und, wofür das ganze? Für Perlen wie diesen Zwischenruf:
Nicolette Kressl [SPD]: Golfstunden! Das ist doch die Welt der FDP!
— Zwischenrufe aus dem Bundestag (@bt_zwischenrufe) February 8, 2019
-
Alle Details zur Geschichte von @horse_ebooks sind kompakt auf der englischsprachigen Wikipedia zusammengefasst: horse_ebooks, abgerufen am 23. März 2019. ↩
-
Craig Timberg und Elizabeth Dwoskin: Twitter is sweeping out fake accounts like never before, putting user growth at risk, Washington Post, vom 6. Juli 2018, abgerufen am 23. März 2019.
Dass dabei jedoch auch Nutzer gesperrt werden können, die keine Bots sind, offenbart die offizielle “Russian Bot”-Liste von Twitter, auf der auch Accounts beinhaltet, hinter denen reale Personen stehen, vgl. Alex Calderwood, Erin Riglin, Shreya Vaidyanathan: How Americans wound up on Twitter’s list of Russian Bots, vom 20. Juli 2018, abgerufen am 23. März 2019. ↩ -
Onur Varol, Emilio Ferrara, Clayton A. Davis, Filippo Menczer und Alessandro Flammini: Online Human-Bot Interactions: Detection, Estimation, and Characterization, letzte Änderung am 27. März 2017, abgerufen am 23. März 2019. ↩
-
Stefan Wojcik, Solomon Messing, Aaron Smith, Lee Rainie und Paul Hitlin: Bots in the Twittersphere, Pew Research Center, vom 9. April 2018, abgerufen am 23. März 2019. ↩
-
Eine optimierte Variante des Codes findet sich im Repository des Projekts. ↩
-
Molly White: How to create a Twitter bot, vom 18. März 2015, abgerufen am 24. März 2019. ↩
-
Vgl. den Hinweis auf der Github-Seite des Projekts heroku-twitterbot-starter, abgerufen am 24. März 2019. ↩

Manuel Häußermann
I'm interested in the intersections between Literature, Culture and the Digital.